In the field of robotic reinforcement learning, the challenge of sim-to-real transfer has been a persistent issue in the training and deployment of algorithms, particularly for tasks requiring large data samples, such as the coordinated control of large-scale drone swarms. The research team from Beihang University has introduced the Air-M platform in this paper, which establishes a mapping from the real world to a simulation environment using the NOKOV motion capture system. This allows real drones to interact with virtual objects through virtual sensors, enabling the policy network to be trained using virtual agents and seamlessly transferred to real drones. The study indicates that the Air-M platform surpasses existing technologies in terms of training efficiency and transferability, making it a promising platform for drone swarm applications.
J. Lou, W. Wu, S. Liao and R. Shi, "Air-M: A Visual Reality Many-Agent Reinforcement Learning Platform for Large-Scale Aerial Unmanned System," 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 2023, pp. 5598-5605, doi: 10.1109/IROS55552.2023.10341405.
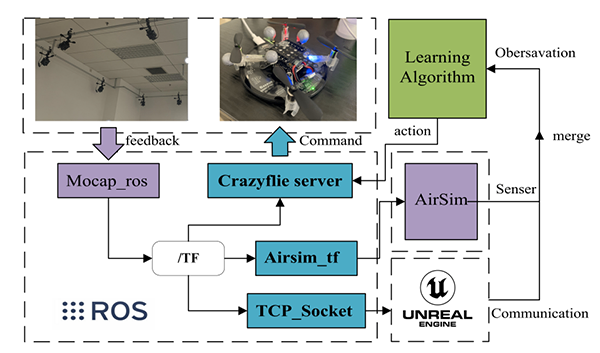
Platform Schema
The schema of Air-M, along with the simulation environment and physical testbed, is illustrated in the following diagram.
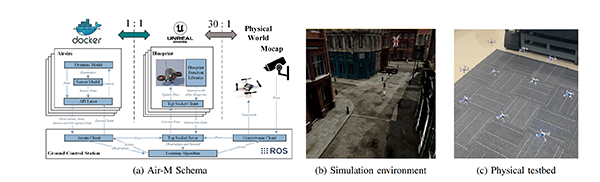
The main components of Air-M, (a) the AirSim container, which provides kinematic and dynamic models, as well as sensor data; (b) the blueprint functions, which offer a communication structure between agents; and (c) the marker points detected by the motion capture system provide the mapping of the real-world to the simulation environment.
A. AirSim Containerization
The research team used docker to encapsulate the AirSim server and its dependence then package them as an image. In addition, we keep the static meshes of different scenarios and compile them into non-editable executable files as the environment backgrounds. When the user starts a container, AirSim will load the local settings file to generate drones of a specified quantity, expose ports and provide services.
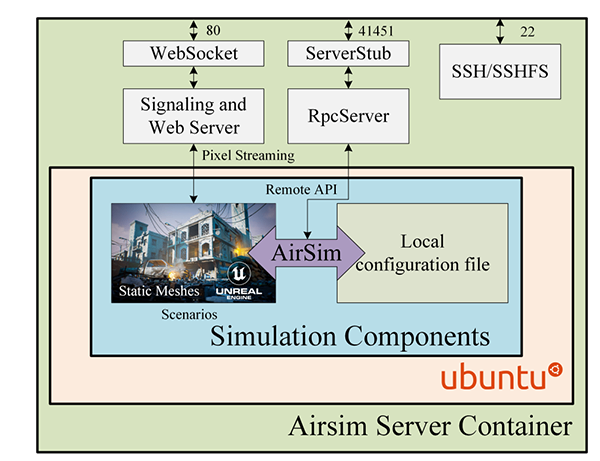
The AirSim container, which can pick different scenarios and configuration files to provide RPC servers and PixelStreaming.
B. Unreal Engine Blueprint Interaction and Communication
Vehicles within the AirSim container are mapped to a shared simulation environment under the assumption that they can communicate with these objects within a limited range. The interaction and communication mechanisms are implemented through UE4 blueprints.
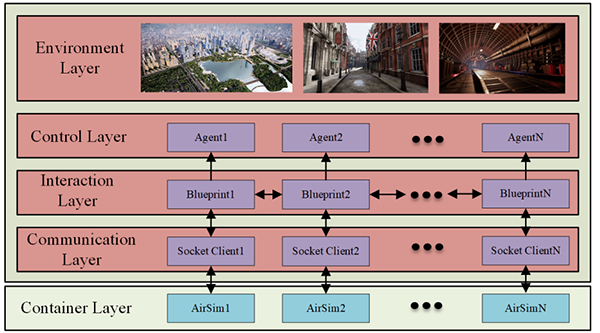
Visualization of the AirSim container and the communication interaction mechanisms between agents.
C. Physical Experimental Testbed
The research team has set up a 3x1 meter indoor testing ground, proportionally mapped to the simulation system. The NOKOV motion capture system provides motion feedback, allowing simulated drones to adjust their positions based on the captured data, thereby facilitating the evaluation of reinforcement learning algorithms.
Physical Experiment Testbed, it contains the external positioning system, the UAV control system, and the UAV ontology.
Experimental Demonstrations
To demonstrate the versatility of the Air-M platform, the research team highlighted its advantages in drone training algorithms through two comprehensive training examples.
Task One: Learning to Search
The objective is to train a swarm of drones to locate crowds in urban streets. The drones are trained offline using centralized information but execute the task in a decentralized manner online. This example showcases the coordinated behavior of a trained drone swarm.

The scenario for training cooperative search, four UAVs generated in the center and the respective mission areas are roughly arranged in advance.
Task Two: Capture Game
The goal is to use 20 trained blue drones to find and capture 20 red drones within a specified time. Upon spotting a target, a drone reports its location to the command center, switches to a tracking algorithm, and calls nearby allies for coordinated capture.
The NOKOV motion capture system provides motion feedback, allowing real drones to interact with virtual sensors and objects, thus facilitating large-scale drone swarm reinforcement learning research.
Author Information
Jiabin Lou: Ph.D. candidate at the School of Computer Science, Beihang University. Research interests include swarm intelligence, multi-agent reinforcement learning, and swarm robotics.
Wenjun Wu: Professor and Ph.D. supervisor at Beihang University. Research interests encompass swarm intelligence and multi-agent systems, cognitive modeling and intelligent tutoring, intelligent cloud services, and intelligent software engineering.
Shuhao Liao: Ph.D. candidate at the School of Computer Science, Beihang University. Research interests include multi-agent reinforcement learning and large models.
Rongye Shi (Corresponding Author): Associate Professor at Beihang University. Research interests include machine learning, reinforcement learning, multiagent systems, and their applications on smart cities and intelligent transportation systems.