At ECAI 2024, the research team from Beihang University published a paper titled “Exploiting Hierarchical Symmetry in Multi-Agent Reinforcement Learning.” The paper presents a novel method called the Hierarchical Equivariant Policy Network (HEPN), which leverages hierarchical symmetry to improve the sample efficiency of MARL algorithms.
To validate the effectiveness of the proposed method, NOKOV motion capture system was utilized to collect real-time environmental state data—specifically, the pose data of unmanned vehicle swarms.
Citation
Tian, Yongkai, et al. "Exploiting Hierarchical Symmetry in Multi-Agent Reinforcement Learning." ECAI 2024. IOS Press, 2024: 2202–2209.
Research Background
Enhancing sample efficiency is a fundamental challenge in reinforcement learning. In the context of MARL, this issue is exacerbated by the exponential growth of the joint state-action space as the number of agents increases. Incorporating symmetry into MARL has proven to be an effective approach to mitigate this problem. However, the concept of hierarchical symmetry—which preserves symmetry across different levels of a multi-agent system—has remained largely unexplored.
Contributions
Focusing on cooperative tasks in multi-agent systems (MAS), this work makes the following contributions:
Proposed the Hierarchical Equivariant Policy Network (HEPN), which utilizes the hierarchical symmetry in MAS to enhance the efficiency of MARL algorithms.
Proposed a partition loss aimed at better uncovering the hierarchical structure within MAS.
Evaluated the performance of HEPN across several multi-agent cooperative tasks. Experimental results indicate that HEPN achieves faster convergence speeds and higher convergence rewards, thereby validating its effectiveness.
Deployed HEPN in a physical multi-robot environment, confirming its effectiveness in real world.

Figure 1 The overall framework of the proposed HEPN consisting of three main modules: 1) Equivariant Cluster Module, used to extract the hierarchical structure in multi-agent systems, clustering agents with similarities into a group to serve as agents in the high-level system; 2) Equivariant Remap Module, used to remap information from the high-level system back to the low-level system; 3) Action Module, used to generate the final action output.
Simulation Experiments
The authors compare HEPN with several baseline methods including: ESP (Exploiting Symmetry Prior), MLP-based MAPPO, GraphSAGE, and GCS (Graph-based Coordination Strategy).
HEPN consistently outperformed all baselines in terms of convergence speed, reward, and scalability. The results demonstrate HEPN’s robustness and effectiveness, particularly in large-scale complex tasks. Ablation studies further revealed that incorporating hierarchy and equivariance significantly enhances performance, especially in tasks with higher complexity.
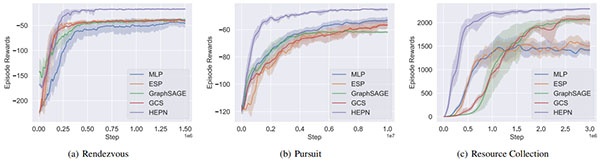
Figure 2 Learning curves for HEPN, MLP, GraphSAGE, ESP, and GCS on three cooperative tasks. Each experiment was repeated five times with different random seeds to ensure robustness.
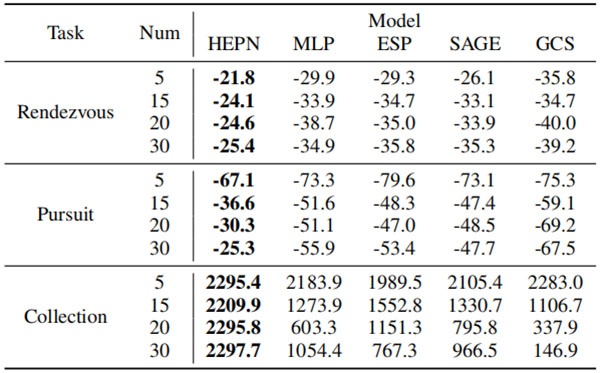
Table 1 Shows the impact of different agent counts on task performance, measured by the average convergence reward.
Real-World Experiment
The paper also evaluates algorithm performance through a Sim2Real approach. The trained models were deployed on physical robots, controlled via ROS, with NOKOV motion capture systems providing real-time pose data for the robot swarm.
Demonstration of Tasks include Rendezvous, Pursuit and Resource Collection
For each task, HEPN was compared against the best-performing baseline. Results demonstrate that HEPN-enabled agents completed tasks more efficiently, thus validating its real-world effectiveness.
NOKOV motion capture system was utilized to obtain real-time environmental state information—specifically, the pose data of unmanned vehicle swarms—which validated the effectiveness of the proposed HEPN algorithm in real-world experiments.
Author Information
Yongkai Tian: PhD candidate, School of Computer Science, Beihang University. Research interests: MARL, knowledge-embedded reinforcement learning.
Xin Yu: PhD candidate, School of Computer Science, Beihang University. Research interests: MARL, large models.
Yirong Qi: Master’s student, School of Computer Science, Beihang University. Research interests: MARL.
Li Wang: PhD candidate, School of Artificial Intelligence, Beihang University. Research interests: MARL, large model reasoning.
Pu Feng: PhD candidate, School of Computer Science, Beihang University. Research interests: MARL, swarm robotics, multi-agent path planning.
Wenjun Wu: Professor at School of Artificial Intelligence, Beihang University. Research interests: swarm intelligence, cognitive modeling, intelligent software engineering.
Rongye Shi: Associate Professor at School of Artificial Intelligence, Beihang University. Research interests: embedded domain knowledge in AI, physics-informed neural networks, MARL applications in smart cities.
Jie Luo: Associate Professor at School of Computer Science, Beihang University. Research interests: software evolution theory, knowledge graph reasoning, swarm intelligence metrics.